들어가며 데이터 분석을 잘아는 PM이 되기위해선 어떡해야할까? 나는 개인적으로 데이터분석 같은 정량적인 내용을 좋아하는 편이다. 시각화로 표현된 데이터들을 통해 고찰하면, 그 고찰이 근거의 힘을 가진다. 아마도 실무에 나가게 된다면 수집된 내부데이터를 잘 가공하여, 자기가 원하는 데이터를 받고, 그를 통해 인사이트를 도출할 수 있는 PM이 데.분을 잘하는 PM이지 않을까? 한다. 오늘은 공공데이터를 통해서 데이터를 가공하고 실습하는 과제를 한다. 곧 내부 데이터를 활용하는 PM이 되기를. 👍
일단 Kaggle(공공데이터)에서 'Netflix Movies and TV Shows' 데이터를 다운 받았다.
넷플릭에서 존재하는 영화와 티비 프로그램의 목록을 확인할 수 있는 데이터베이스다.
이 데이터베이스에서 확인할 수 있는 데이터 목록은 다음과 같다.
| show_id | type | title | director | cast | country | date_added | release_year | rating | duration | listed_in | description |
show_id : 구분을 위한 고유 아이디
type : 장르
title : 제목
director : 감독
cast : 배우
country : 제작한 나라
date_added : 업로드 날짜
release_year : 업로드 년도
duration : 러닝타임
listed_in : 장르
description : 내용
이 내용들을 통해서 내가 확인할 수 있는 가설 3가지를 세워보았다.
가설
1. 넷플릭스에서 가장 많이 IP를 보유하고 있는 국가는 미국일것이다
2. 넷플릭스에 올라온 영화 중에서 5년동안 '액션' 장르가 증가했을것이다
3 : 넷플릭스에 올라온 영화의 러닝타임이 90분 이하가 더 많을 것이다
이제 이 데이터베이스를 구글 빅쿼리로 가져가서, 쿼리문을 통해 내가 원하는대로 가공을 해볼 것이다!
각 가설별로 어떻게 추출하고 가공했는지 서술했다.
가설 1: 넷플릭스에서 가장 많이 IP를 보유하고 있는 국가는 미국일것이다
조건
: country 데이터만 추출, 가장 많은 갯수별로 순위화한다.
1) 빅쿼리를 이용하여 데이터 추출
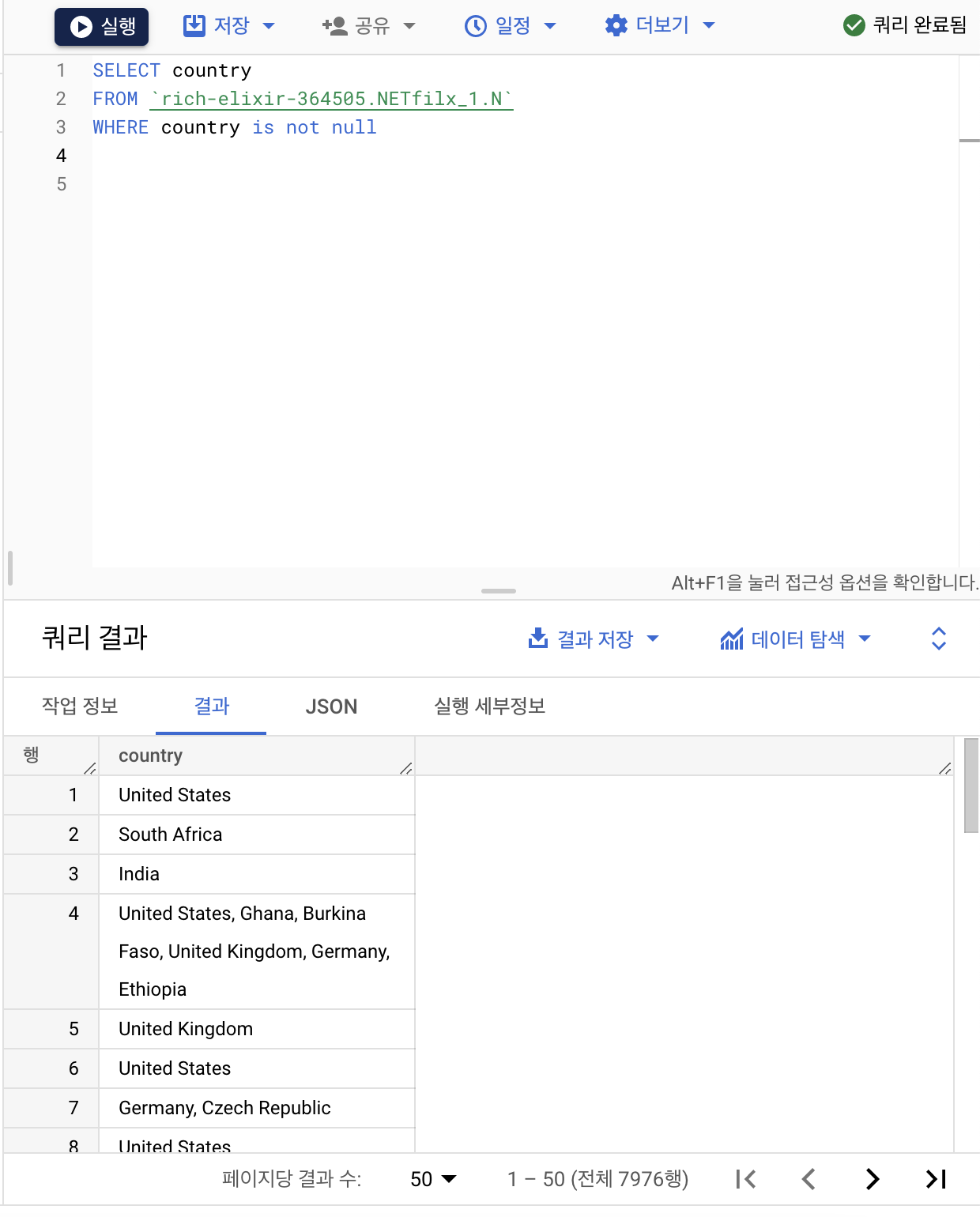
: 데이터 베이스 안에 'Country' 값 전부 추출 (WHERE)
: Country 데이터에 null 값이 포함되어 있어서 조건문을 통해 null 값을 제거 (is not null)
이렇게 빅쿼리에서 추출된 데이터는 아래의 결과값에서 나오게 되어있다. 하지만 이건 데이터를 추출만 한 것이지 시각화했다고 볼 수가 없다! 이 데이터를 가지고 각 조건값(Country)을 가진 데이터가 몇개씩 있는지 표로 살펴볼 수 있다.
2) 데이터 시각화

데이터 스튜디오를 통해 갯수별 열차트 순위 생성를 생성했다. Country 조건값을 가진 데이터가 몇개씩 되는지, 즉 각 나라별 보유하고 있는 IP의 순위와 갯수를 볼 수 있다.
United States - 1위 (약 2.8천)
India - 2위 (약 9천)
따라서 앞에서 세웠던 가설은 진실이라고 확인되었다.
1. 넷플릭스에서 가장 많이 IP를 보유하고 있는 국가는 미국일것이다 (진실)
가설 2 : 넷플릭스에 올라온 영화 중에서 5년동안 액션' 장르가 증가했을것이다
다음 조건의 데이터를 추출한다.
: 2022년 데이터가 존재하지 않음으로 릴리즈년도를 2021~2017년도 5개년 데이터를 비교한다
조건
Tybe(종류) : Movie
release_year(릴리즈 년도) : 2017~2021
listed_in(장르 리스트) : 'Action & Adventure' 포함
결과
각 release_year(릴리즈 년도)별 갯수
1) 빅쿼리를 통한 데이터 추출
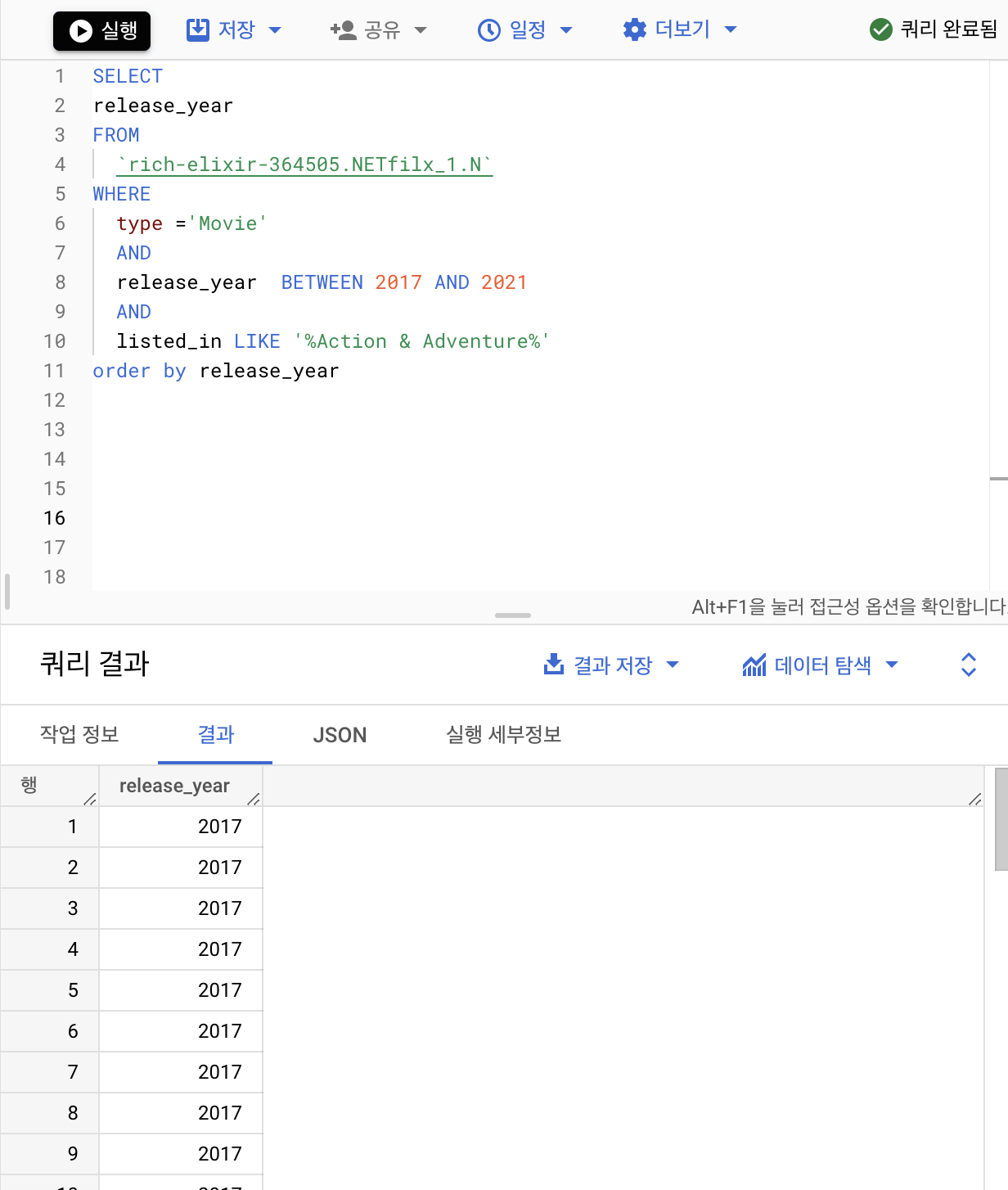
쿼리문 해설
SELECT = 추출할 데이터 = release_year
WHERE = 해당 추출할 데이터에 걸릴 조건문
WHERE
type ='Movie'
AND
release_year BETWEEN 2017 AND 2021
AND
listed_in LIKE '%Action & Adventure%'
Type(장르)은 'Movie'만 추출
release_year(연도)는 2017~2021년도만 추출 (BETWEEN A AND B : A~B 사이)
listed_in(장르 리스트)는 'Action & Adventure'라는 단어 포함한 데이터 추출 (%A%: A라는 단어 포함)
2) 데이터 시각화
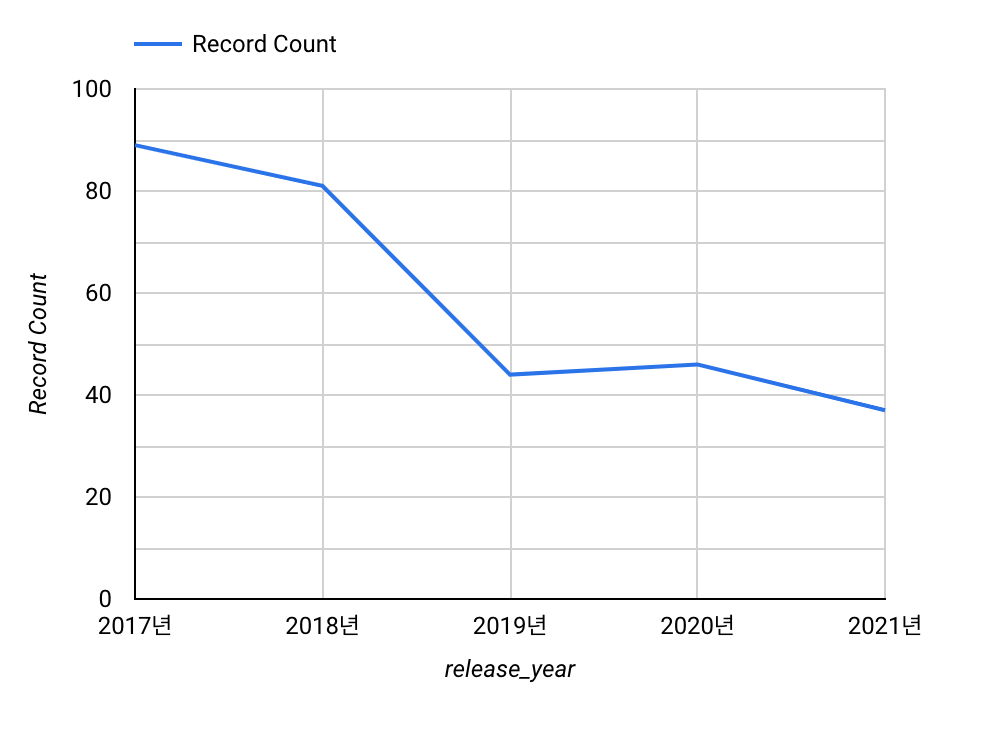
X축 = release_yera(릴리즈 년도)
Y축 = 갯수
실제로 2017년도에서 2021년도까지 '액션&어드벤쳐' 장르 영화 갯수가 오히려 줄어들었다
가설 2 : 넷플릭스에 올라온 영화 중에서 5년동안 '액션' 장르가 증가했을것이다(거짓)
가설 3 : 넷플릭스에 올라온 영화의 러닝타임이 90분 이하가 더 많을 것이다
조건
Tybe(종류) : Movie
duration : <90, >90
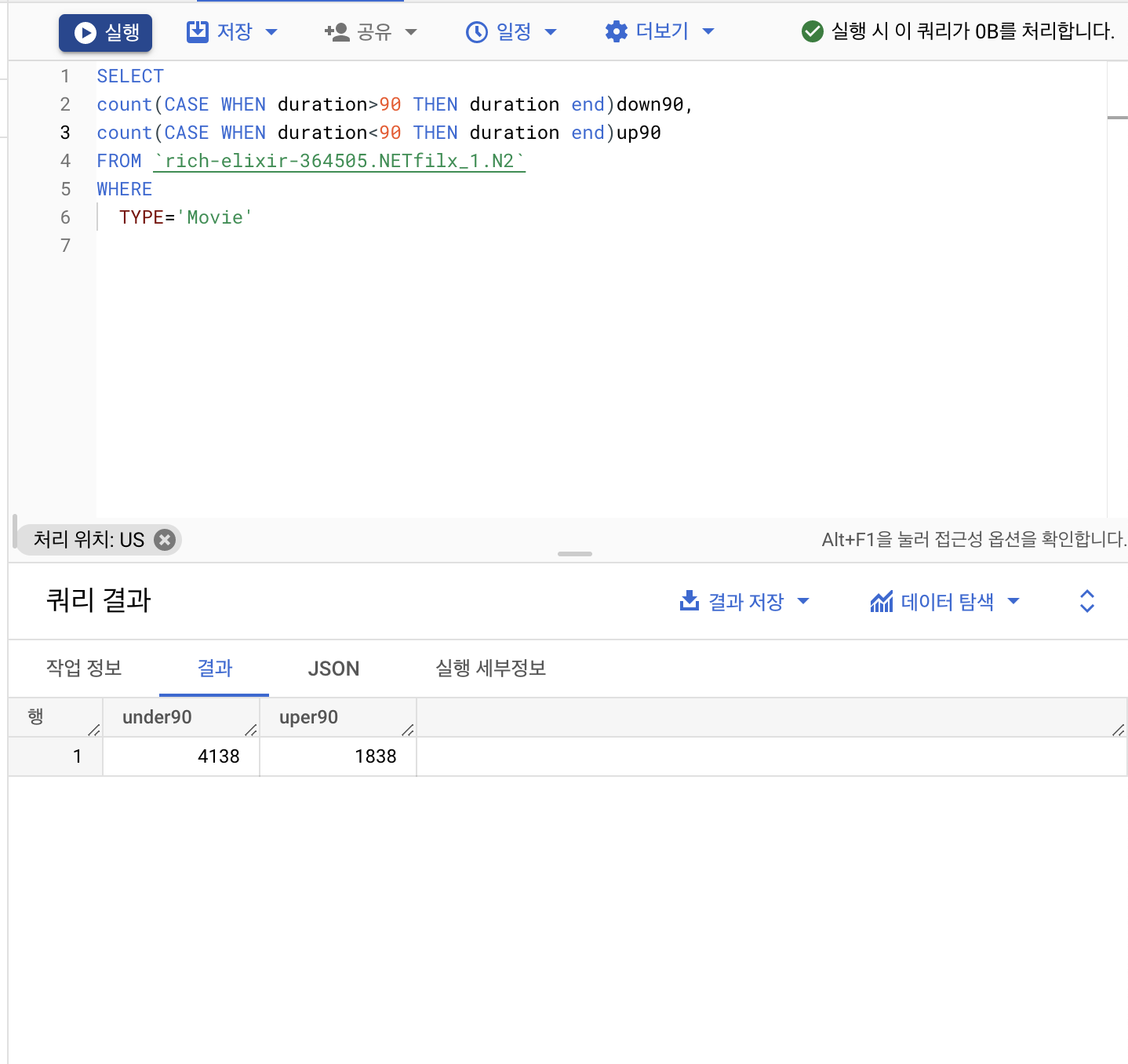
쿼리문 해설
(CASE WHEN = 조건절, 조건에 맞을때만 출력)
2) 데이터 시각화
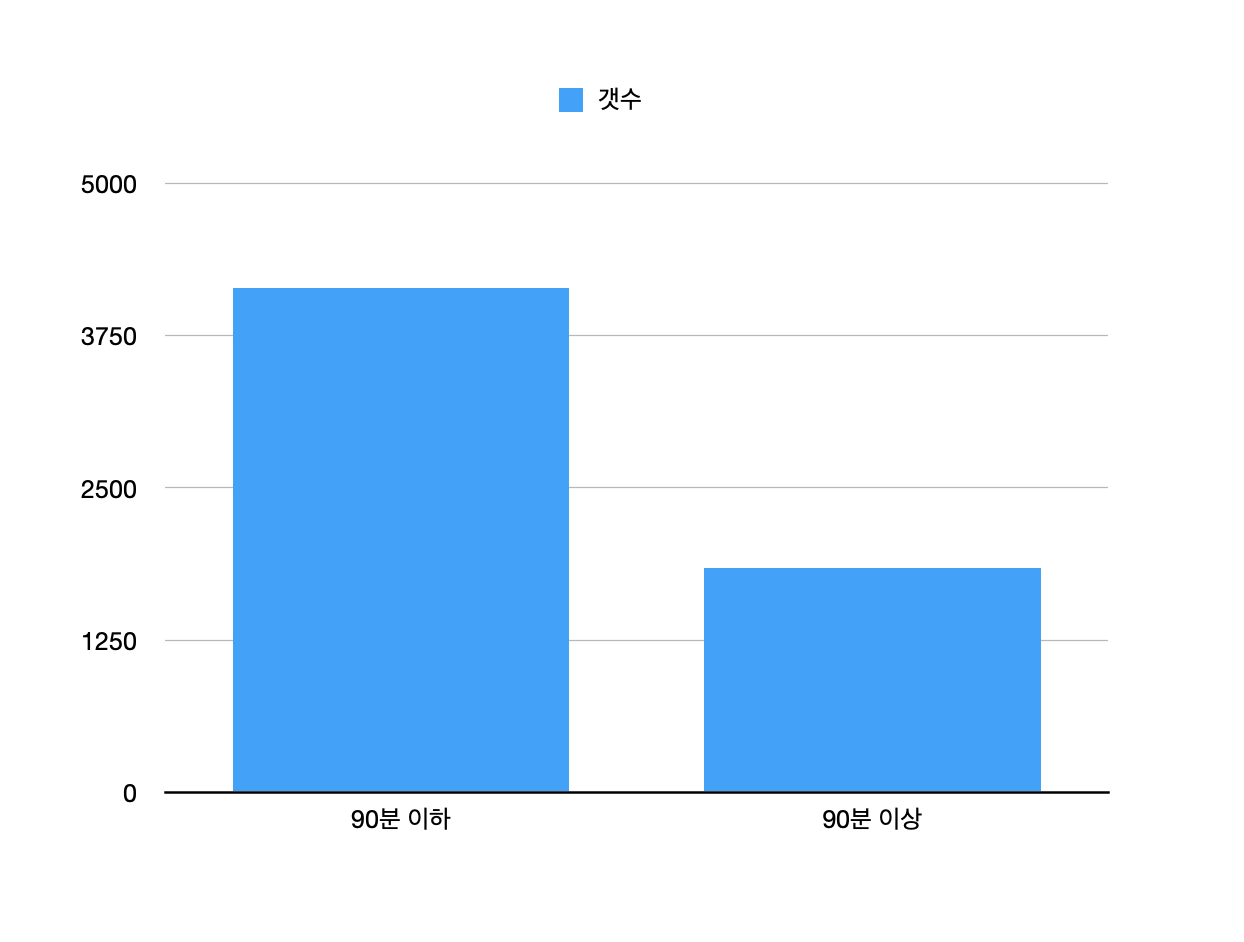
두개의 갯수를 합쳐서 표로 만들면 다음과 같다. 보시다시피 90분 이하의 영화 갯수가 훨씬 더 많다.
가설 3 : 넷플릭스에 올라온 영화의 러닝타임이 90분 이하가 더 많을 것이다 (진실)
회고 데이터 분석을 잘아는 PM으로 거듭나기 위해서 드디어 데이터 분석 실습으로 들어왔다. 나는 아직 데이터 분석의 우매함의 봉우리 과정을 지나고 있기 때문에 (ㅋㅋ) 쿼리문을 통해서 원하는 데이터를 추출하는게 생각보다는 재밌다. SQL을 살짝 배워놓고 쓸데가 없어서 실습은 전혀 못하고 있는데 이번 기회에 써봐서 또 재밌기도 하다.
'코드스테이츠 PMB 14기 > DAILY' 카테고리의 다른 글
| [코드스테이츠 PMB 14기] 앱의 4가지 형태를 알아보자 (0) | 2022.10.09 |
|---|---|
| [코드스테이츠 PMB 14기] 개발을 아는 PM이 되고 싶어요. (feat. 프론트엔드, 티스토리) (1) | 2022.10.06 |
| [코드스테이츠 PMB 14기] 포스타입으로 하는 린 Lean 분석 (1) | 2022.09.30 |
| [코드스테이츠 PMB 14기] GA로 확인하는 '유튜브 뮤직'의 데이터 예측 (0) | 2022.09.29 |
| [코드스테이츠 PMB 14기] 데이터를 아는 기획자가 되기 첫걸음 (0) | 2022.09.28 |




댓글